 |
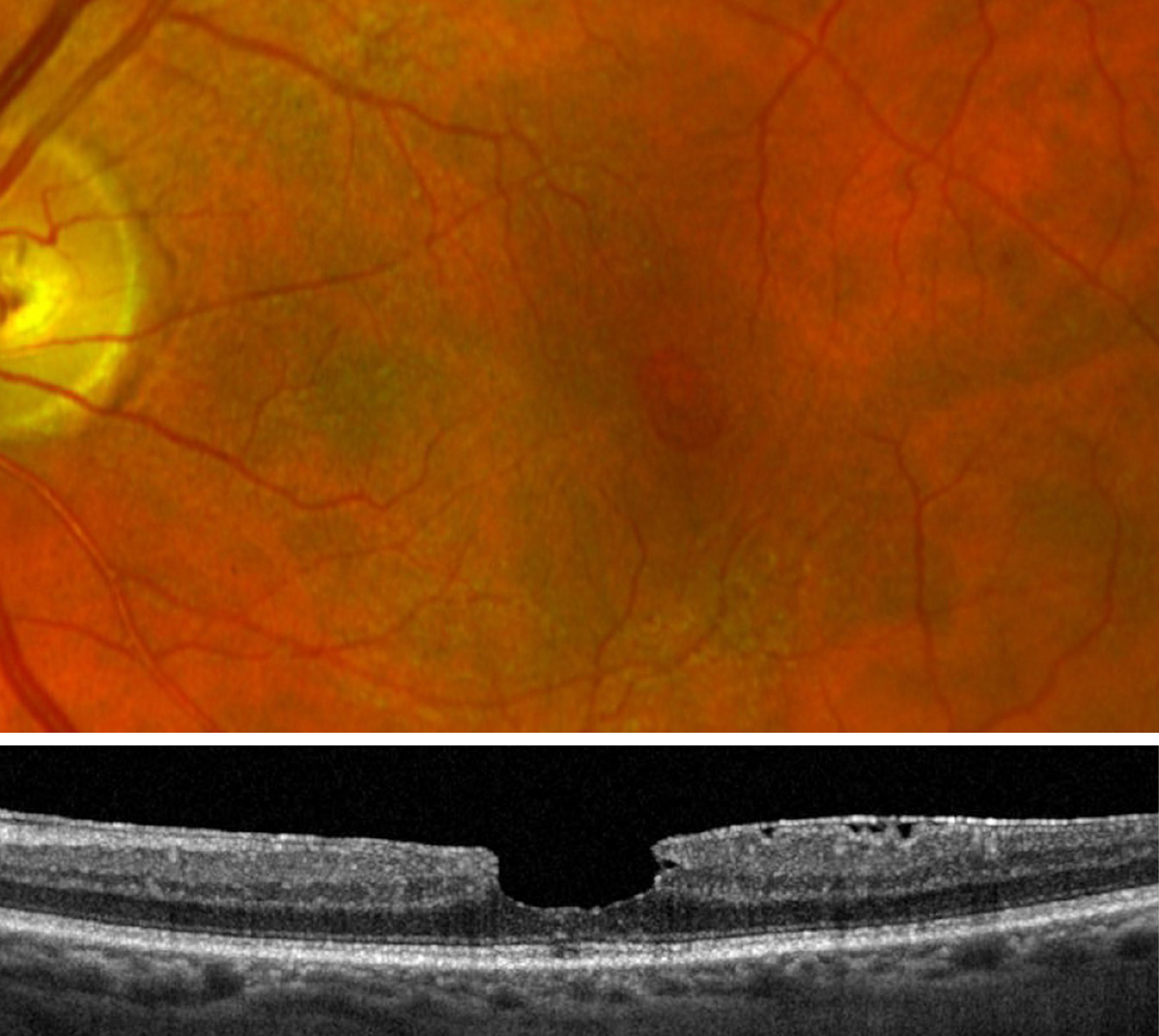
The chatbot provided interpretations of ophthalmic images beyond information explicitly stated in the source database in some instances. One case presented to it and discussed in the journal article was macular pseudohole. Photo: Jessica Haynes, OD. Click image to enlarge. |
Another week, another ChatGPT study, it seems. After the AI-powered tool made headlines for beating retina and glaucoma specialists and holding its own against cornea specialists comes a report on its capabilities in evaluating clinical photos, something that seems ideally suited for AI. Researchers used a publicly available dataset of ophthalmic cases from OCTCases—a medical education platform based from the Department of Ophthalmology and Vision Sciences at University of Toronto—along with clinical multimodal imaging and multiple-choice questions. Of the 137 cases, 136 had multiple-choice questions.
Included in the analysis alongside the 136 cases were 429 total multiple-choice questions and 448 images. The questions were answered at an accuracy of 70% overall (n=299). Performance of the chatbot was best on retina questions (77% correct) and worst on neuro-ophthalmology questions (58% correct). Intermediate performance was seen in categories of ocular oncology (72% correct), pediatric ophthalmology (68% correct), uveitis (67% correct) and glaucoma (61% correct). Additionally, ChatGPT was significantly better at answering questions that were non-image based (82%) vs. image-based (65%).
Expanding on this last point, the researchers, writing in JAMA Ophthalmology, wanted to test this prowess in the ophthalmic field. To do this, they relay that this was particularly evident in the pediatric ophthalmology category, suggesting the image-processing capabilities are, right now, less robust in niche subspecialties. Despite this shortcoming, the results here do support the potential of ChatGPT to relatively interpret findings from many ophthalmic imaging modalities, including OCT, OCT-A, fundus images, RNFL analyses, visual field testing, FAF, IVFA and GCC analyses.
Similarly to the subpar analysis of pediatric ophthalmology images, ChatGPT performed worst in the subspecialty of neuro-ophthalmology. The authors explain this may be due to imaging modalities generally used for neuro-ophth vs. the retina, which was the best-performed category. As the retinal category largely consisted of macular OCT and fundus images, “it is plausible that the current release of the chatbot may be better equipped in interpreting more widely used ophthalmic imaging modalities” compared with neuro-ophthalmology’s higher proportion of RNFL and GCC OCT images, they wrote.
This may be the first study using ChatGPT to interpret ophthalmic images, but the chatbot has already been used in the ophthalmic field for other purposes. In a previous study, pitting it against 125 text-based multiple-choice questions used by trainees to prepare for ophthalmology board certification, the previous version of ChatGPT answered 46% these questions correctly. Two months later, this measure rose to 84% accuracy. Reflective of this improvement, the authors posit: “Given that this is a novel addition to the chatbot’s platform, we anticipate its performance on image-based questions may increase considerably with time, as was previously observed in our analyses of text-based questions.”
While the performance of ChatGPT in this investigation achieved moderate accuracy, the large learning model is still inferior to previously published AI systems designed for screening or diagnosing retinal pathologies from ophthalmic imaging like OCT scans and fundus images. However, incorporating more robust AI algorithms into the chatbot may further improve their multimodal capabilities.
The authors warn that with this great technology becoming increasingly widespread, “it is imperative to stress their appropriate integration within medical contexts.” However, they look to a future where “as the chatbot’s accuracy increases with time, it may develop the potential to inform clinical decision-making in [eyecare settings] via real-time analysis of ophthalmic cases.”
Mihalache A, Huang RS, Popovic MM, et al. Accuracy of an artificial intelligence chatbot’s interpretation of clinical ophthalmic images. JAMA Ophthalmol. February 29, 2024. [Epub ahead of print]. |